
Anthropic mění nasazení Claude Fable 5 a zvedá laťku bezpečnostních filtrů. V praxi to znamená méně průchozích rizikových dotazů, ale také více blokovaných benigních požadavků.


Claude Fable 5 dostává přísnější bezpečnostní režim a Anthropic tím dává jasně najevo, že u modelu teď preferuje opatrnost před maximální průchodností. Pro běžné firmy i vývojáře to znamená jednu věc: část dotazů, které dřív prošly, může nově skončit blokací, pokud se budou jevit jen trochu rizikově.
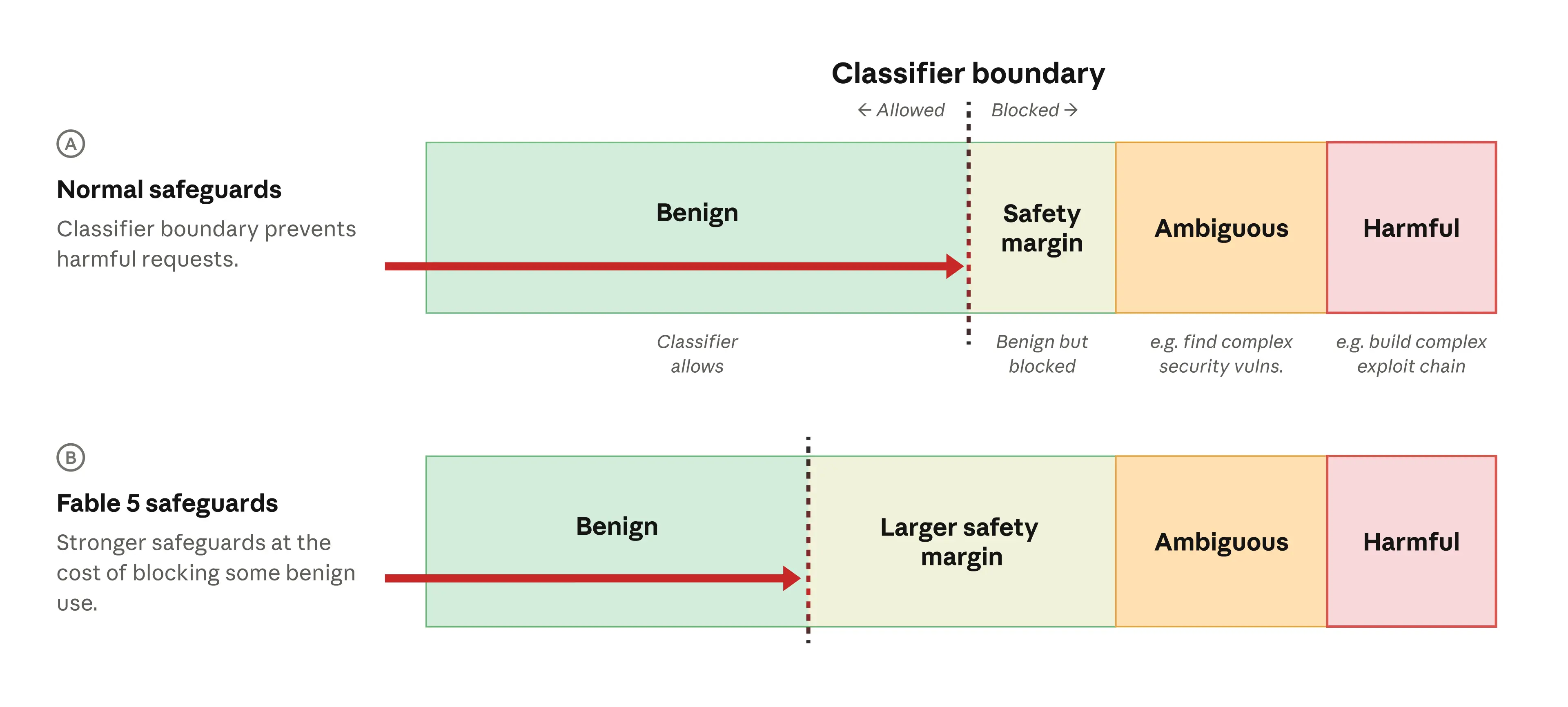 An illustration of our cybersecurity safety classifiers. When a request is made to the model, the classifiers detect whether it is benign (and allowed), or potentially harmful (and blocked). The classifiers block ambiguous requests (those that are clearly to do with cybersecurity but could potentially be for defensive purposes, like finding security vulnerabilities) and harmful requests (those that are clearly dangerous, such as a request to build a chain of software exploits). As shown in row A, we also include a “safety margin”, where the classifier will block requests that are probably benign but have some small chance of being harmful. This increases our confidence that all harmful requests will be blocked. For Fable 5 (row B) we made the safety margin even larger, meaning that more benign requests would be blocked—but fewer genuinely harmful requests would be missed. “Vulns” = vulnerabilities.
An illustration of our cybersecurity safety classifiers. When a request is made to the model, the classifiers detect whether it is benign (and allowed), or potentially harmful (and blocked). The classifiers block ambiguous requests (those that are clearly to do with cybersecurity but could potentially be for defensive purposes, like finding security vulnerabilities) and harmful requests (those that are clearly dangerous, such as a request to build a chain of software exploits). As shown in row A, we also include a “safety margin”, where the classifier will block requests that are probably benign but have some small chance of being harmful. This increases our confidence that all harmful requests will be blocked. For Fable 5 (row B) we made the safety margin even larger, meaning that more benign requests would be blocked—but fewer genuinely harmful requests would be missed. “Vulns” = vulnerabilities.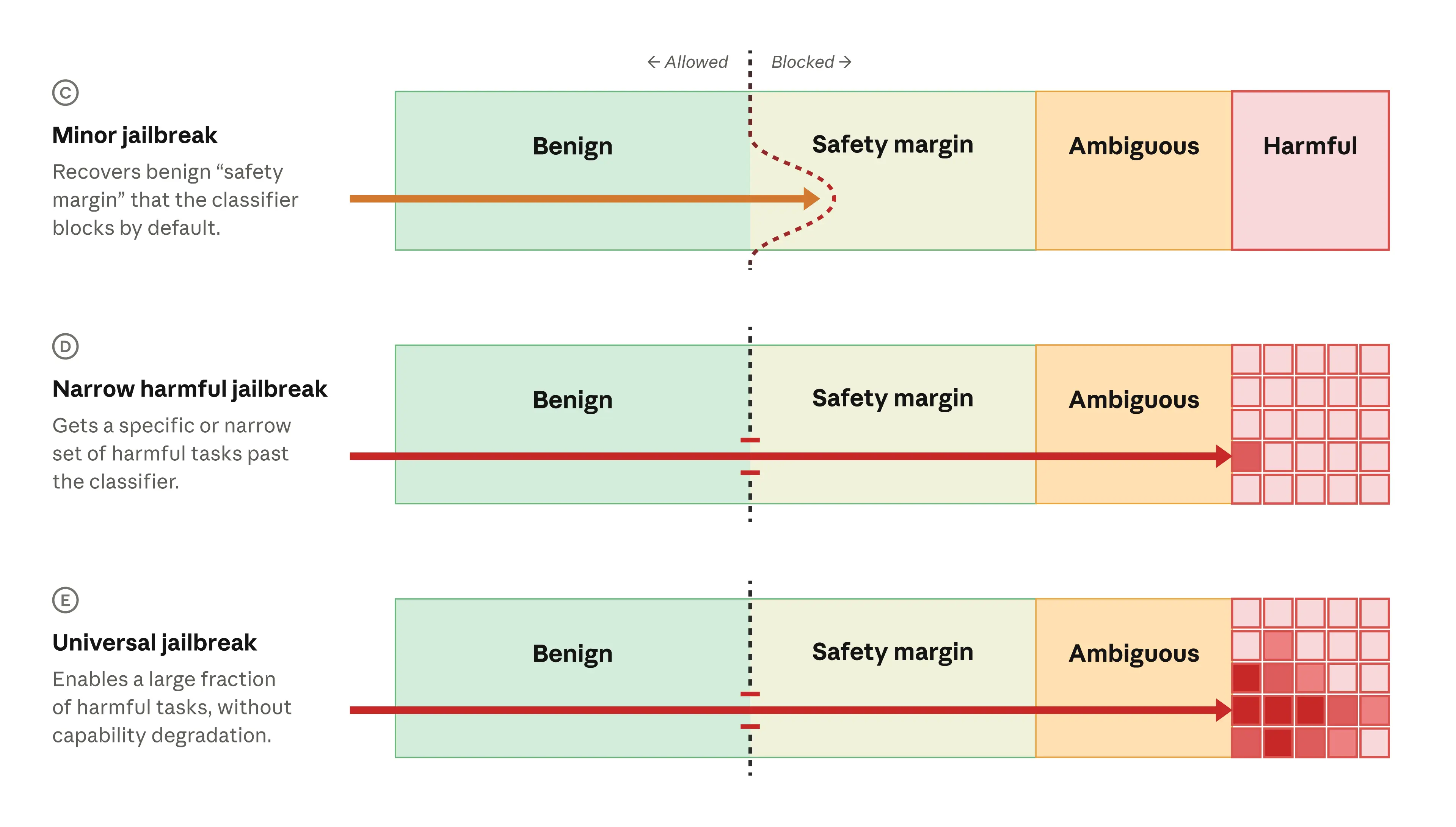 How jailbreaks interact with our safety classifiers. In the case of a minor jailbreak (row C), the classifiers do not block the request, but the request is still within our safety margin (and is thus very unlikely to be harmful). In a narrow harmful jailbreak (row D), the prompt breaches the classifiers and unblocks a specific harmful behavior from the model. In a universal jailbreak (row E), a prompt unblocks an entire class of harmful behaviors.
How jailbreaks interact with our safety classifiers. In the case of a minor jailbreak (row C), the classifiers do not block the request, but the request is still within our safety margin (and is thus very unlikely to be harmful). In a narrow harmful jailbreak (row D), the prompt breaches the classifiers and unblocks a specific harmful behavior from the model. In a universal jailbreak (row E), a prompt unblocks an entire class of harmful behaviors.Bezpečnostní filtr je tvrdší než dřív
Podstata změny je poměrně přímočará. Anthropic rozšiřuje takzvanou bezpečnostní rezervu svých klasifikátorů, tedy prostoru, ve kterém raději zablokují i dotazy, jež jsou pravděpodobně neškodné, ale nesou malé riziko zneužití. Cílem je snížit šanci, že model propustí skutečně škodlivý požadavek.

U Fable 5 je tato rezerva větší než dřív. V praxi to znamená přísnější posuzování zejména u zadání z oblasti kyberbezpečnosti, kde je hranice mezi legitimním testováním a nebezpečným zneužitím často tenká. Pokud systém vyhodnotí žádost jako ambivalentní, raději ji zablokuje.
Anthropic zároveň popisuje, jak se bezpečnostní filtry chovají při pokusech o obejití ochrany. Menší jailbreaky nemusí nutně nic spustit, ale stále se mohou vejít do bezpečné zóny. Naopak úspěšný jailbreak může odemknout konkrétní škodlivé chování, nebo dokonce širší skupinu rizikových odpovědí, což je přesně scénář, kterému chce firma zabránit.
Co to znamená pro firmy a běžné uživatele
Největší dopad pocítí týmy, které Claude používají v enterprise prostředí. U standardních licencí Fable 5 není automaticky součástí předplatného a bez povolených kreditů k němu uživatelé přístup mít nebudou. U prémiových podnikových seatů zůstává do 7. července součástí balíčku, poté se přístup může dál odvíjet právě od zapnutých kreditů.
Pro firmy je to důležité hlavně z pohledu provozu. Přísnější filtr sice může občas zdržet legitimní práci, ale zároveň snižuje riziko, že se model nechá zlákat k produkci nebezpečného obsahu. U nástrojů, které se používají při programování, bezpečnostním výzkumu nebo automatizaci interních procesů, je podobná pojistka prakticky zásadní.
Pro běžné uživatele jde o připomínku širšího trendu v AI: čím schopnější modely jsou, tím pečlivěji se hlídá, co mohou generovat. Anthropic tímto krokem staví bezpečnost nad pohodlí a vychází z předpokladu, že je lepší několik falešných poplachů navíc než jeden nebezpečný průchod. V prostředí, kde se velké jazykové modely čím dál častěji používají i v citlivějších scénářích, je to logický, i když ne úplně bezbolestný posun.
Podrobnosti přinesl také Anthropic.











Chcete k tomu něco dodat? Napište krátce proč.